Supercharge Your AI: Feed Your Own Knowledge into LLMs
Ever wondered how to make large language models (LLMs) work specifically for you? Whether you're running a local LLM on your own machine or connecting to a cloud-based one, incorporating your personal data and documents can supercharge its performance — improving relevance, accuracy, and utility.
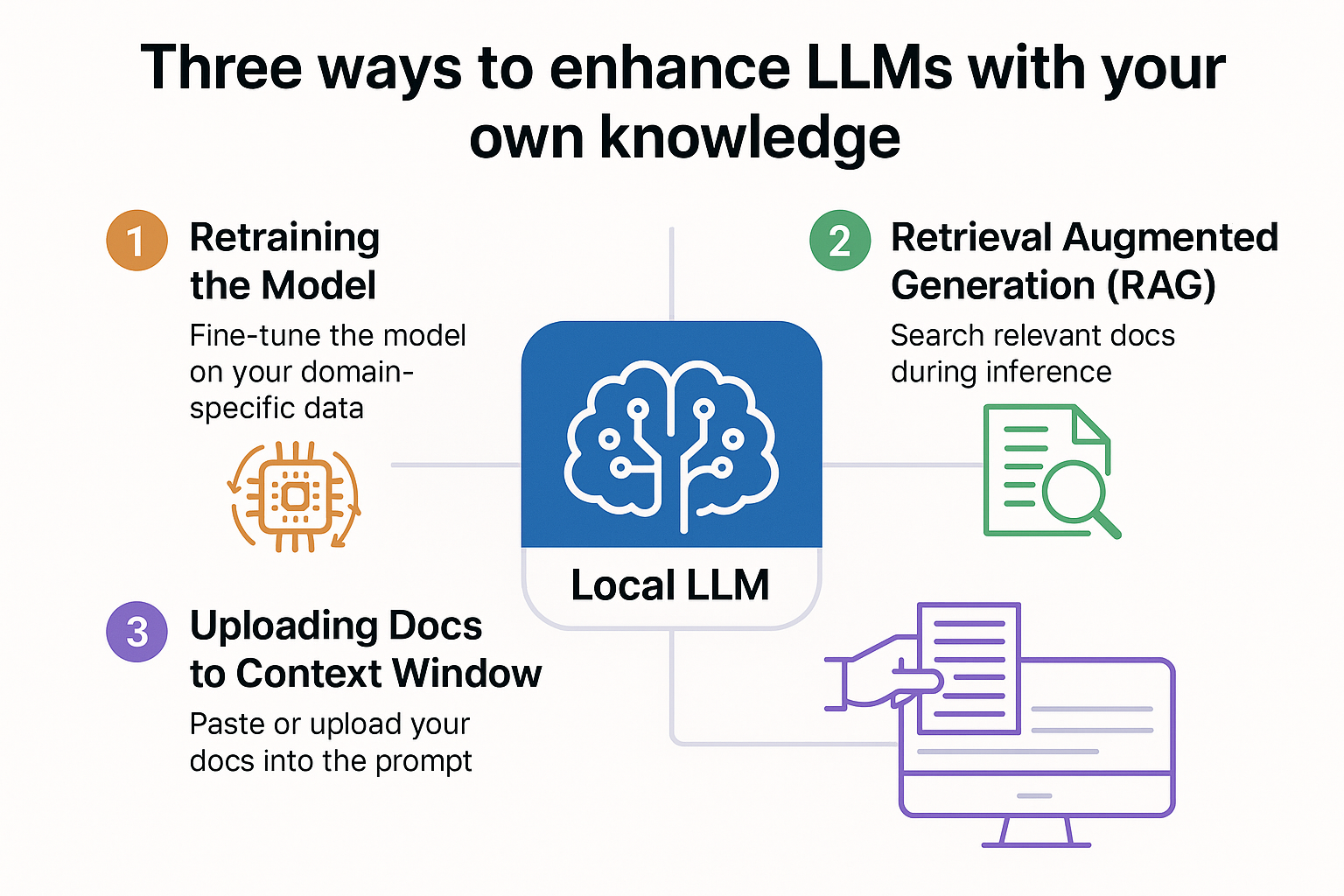
In this guide, we’ll explore one of the most transformative ideas in AI today: infusing your own knowledge into LLMs. There are three core ways to do this, each with different levels of complexity and power:
- Retraining the Model: Fine-tune the LLM directly with your domain-specific data.
- Retrieval-Augmented Generation (RAG): Let your model find and use your documents during inference.
- Context Injection: Simply paste or upload your content into the prompt at runtime.
Whether you're building a personalized chatbot, an internal company tool, or a research assistant, understanding these strategies will help you unlock your model’s true potential.
Let’s dive in and explore how each method works — and when to use which.
Understanding the Landscape
When you want to feed new information to a large language model, you essentially have three main options:
1. Retraining the Model
Think of retraining as sending a student back to school to learn new material or correct mistakes. The model undergoes a thorough process of learning, incorporating new data into its core understanding permanently.
Pros
- Permanent knowledge integration
- Available for every future interaction
- Most thorough understanding
Cons
- Requires massive computational resources
- Needs access to model weights
- Time-consuming process
2. Retrieval Augmented Generation (RAG)
RAG is a clever middle ground where the model dynamically consults an external database or document repository when answering questions. Imagine a student who doesn't remember everything but knows exactly where to find the right book in the library instantly.
Pros
- Handles large and evolving datasets
- Lower computational overhead
- Scalable for complex information
Cons
- Requires document indexing
- Slightly slower response time
- Needs proper setup
3. Uploading Documents to Context Window
The simplest method where you upload files directly into the model's current session. The model can reference these documents during your conversation, like a student glancing at a cheat sheet during an exam.
Pros
- Quick and easy to implement
- No additional setup required
- Immediate results
Cons
- Temporary knowledge only
- Limited by context window size
- Manual upload each session
Why Retraining Isn't Always Practical
Retraining requires specialized hardware like Nvidia A100 GPUs and expertise in machine learning frameworks. For closed-source models like ChatGPT, it's often impossible without API access. Even with open models like LLaMA 3.2, the process demands:
- Multi-GPU setups (RTX 6000 or similar)
- Advanced programming skills
- Days or weeks of training time
- Careful dataset preparation
For most users, RAG or context window uploads provide more practical solutions.
Practical Implementation Guide
Uploading Documents to ChatGPT
Click the paperclip icon
Upload your document (PDF, Word, etc.) directly in the chat interface.
Ask your question
Reference specific content from your uploaded document.
Get contextual answers
ChatGPT will reference your document to provide accurate responses.
Creating Custom GPTs
For a more permanent solution within ChatGPT:
Go to "Explore GPTs"
Click "Create" to start building your custom assistant.
Upload your documents
Add all relevant files (manuals, guides, datasets).
Configure your GPT
Give it a name, description, and specific instructions.
Local Setup with LLaMA 3.2
For complete control over your data:
Install Open Web UI
Set up the interface on your local machine.
Upload documents
Through the document management interface.
Enable RAG
Configure the system to reference your documents.
Method Comparison
| Method | Best For | Difficulty | Knowledge Duration |
|---|---|---|---|
| Retraining | Permanent updates | Expert | Permanent |
| RAG | Large/dynamic data | Intermediate | Persistent |
| Context Upload | Quick queries | Beginner | Temporary |
Final Recommendations
For Beginners
Start with ChatGPT document uploads or custom GPTs. The interface is user-friendly and requires no technical setup.
For Intermediate Users
Experiment with local LLaMA models and Open Web UI. You'll gain more control and privacy for your documents.
For Advanced Users
Implement RAG systems for large-scale document integration. Consider tools like ChromaDB or Weaviate for better performance.
"By creating a custom GPT with your documents embedded in it, it will use retrieval augmented generation as it answers your questions."